Dentro del algoritmo de recomendación open source de X: ¿Qué tipo de contenido logra captar la atención?
La tarde del 20 de enero, X liberó como código abierto su último algoritmo de recomendación.
Musk comentó: “Sabemos que este algoritmo es poco inteligente y aún necesita grandes mejoras, pero al menos podéis ver que trabajamos para mejorarlo en tiempo real. Ninguna otra plataforma social se atrevería a hacer esto”.
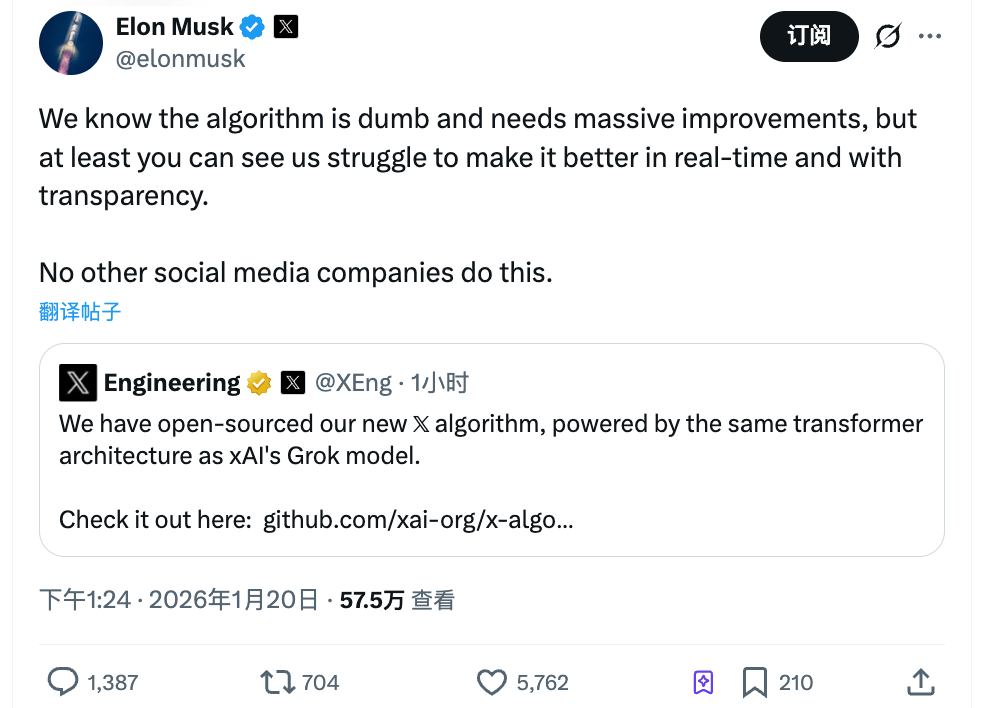
Su declaración tiene dos claves: reconoce las carencias del algoritmo y apuesta por la transparencia como valor diferencial.
Es la segunda vez que X publica su algoritmo como código abierto. La versión de 2023 llevaba tres años sin actualizaciones y estaba desconectada del sistema productivo. Ahora, el código se ha reescrito por completo. El modelo central ha pasado del aprendizaje automático tradicional al transformador Grok. Según la descripción oficial, “se ha eliminado por completo la ingeniería manual de características”.
En resumen: el algoritmo anterior dependía de ajustes manuales de parámetros por parte de los ingenieros. Ahora, la IA analiza directamente tu historial de interacción para decidir si promociona tu contenido.
Para los creadores de contenido, esto implica que estrategias como “horarios óptimos de publicación” o “qué etiquetas hacen crecer seguidores” pueden dejar de funcionar.
También revisamos el repositorio abierto en GitHub y, con ayuda de la IA, detectamos lógica codificada relevante para analizar.
Evolución de la lógica algorítmica: de reglas manuales a juicio basado en IA
Primero, diferenciemos la versión anterior y la nueva para evitar confusiones.
En 2023, el algoritmo abierto de Twitter se llamaba Heavy Ranker. Era aprendizaje automático tradicional: los ingenieros definían manualmente cientos de características (si la publicación tenía imágenes, número de seguidores del autor, antigüedad de la publicación, si incluía enlaces, etc.).
Cada característica recibía un peso, que se ajustaba continuamente en busca de la combinación óptima.
La nueva versión abierta se llama Phoenix. Su arquitectura es radicalmente distinta: depende mucho más de modelos de IA de gran escala. El núcleo utiliza el transformador Grok, la misma tecnología que impulsa ChatGPT y Claude.
El README oficial lo deja claro: “Hemos eliminado todas las características diseñadas a mano”.
El sistema anterior, basado en reglas y en la extracción manual de características, ha desaparecido.
¿Y ahora cómo se juzga si un contenido es bueno?
La respuesta: tu secuencia de comportamiento. Qué te gusta, a quién respondes, en qué publicaciones permaneces más de dos minutos, qué cuentas bloqueas. Phoenix alimenta estos datos al transformador, que aprende y resume los patrones.
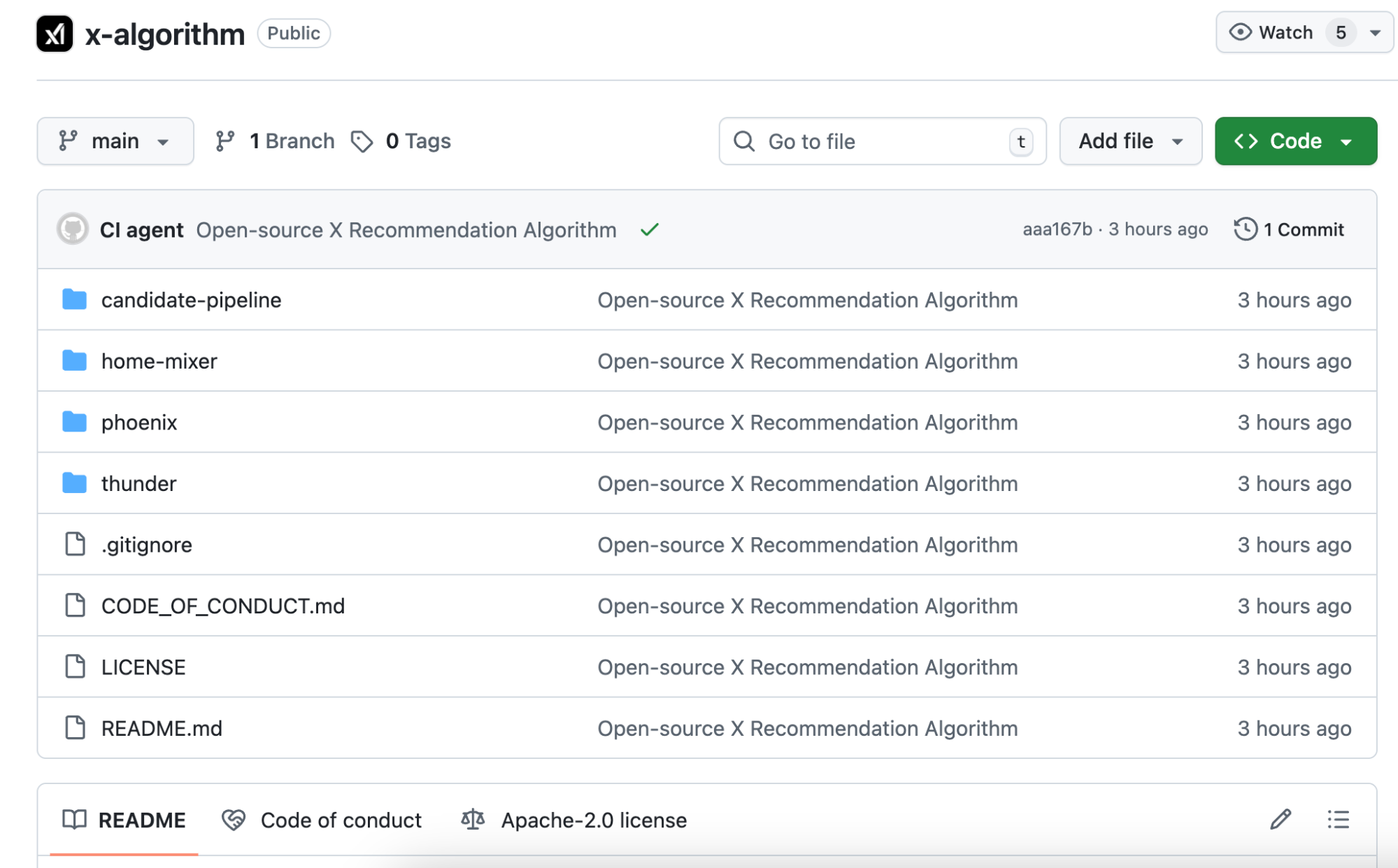
Por ejemplo, el algoritmo antiguo era como una hoja de puntuación manual, asignando puntos por cada criterio.
El nuevo algoritmo es como una IA con acceso a todo tu historial de navegación, que predice qué querrás ver a continuación.
Para los creadores, esto supone dos cosas:
Primero, tácticas como “mejor horario de publicación” o “etiquetas doradas” pierden relevancia. El modelo ya no mira características fijas, sino preferencias personales de cada usuario.
Segundo, la promoción del contenido depende mucho más de “cómo reaccionan los usuarios”. Estas reacciones se cuantifican en 15 tipos de predicciones de comportamiento, que detallamos a continuación.
El algoritmo predice 15 tipos de reacciones de usuario
Cuando Phoenix evalúa una publicación, predice 15 posibles acciones de usuario:
- Acciones positivas: dar me gusta, responder, republicar, citar republicación, hacer clic en la publicación, hacer clic en el perfil del autor, ver más de la mitad de un vídeo, expandir imagen, compartir, permanecer cierto tiempo, seguir al autor
- Acciones negativas: seleccionar “no me interesa”, bloquear al autor, silenciar al autor, reportar
Cada acción tiene una probabilidad estimada. Por ejemplo, el modelo puede prever un 60 % de probabilidad de que des me gusta y un 5 % de que bloquees al autor.
El algoritmo multiplica cada probabilidad por su peso y suma los resultados para obtener la puntuación final.
La fórmula es:
Puntuación final = Σ (peso × P(acción))
Las acciones positivas suman; las negativas restan.
Las publicaciones con mayor puntuación se posicionan arriba; las de puntuación baja, abajo.
En la práctica, la “bondad” del contenido ya no depende solo de su calidad intrínseca (aunque la legibilidad y el valor siguen siendo necesarios para que se comparta). Ahora depende de “las reacciones que provoca”. El algoritmo no se interesa por el contenido, sino por el comportamiento del usuario.
Así, en casos extremos, una publicación de baja calidad con muchas respuestas puede superar en puntuación a una publicación de alta calidad sin interacción. Este parece ser el razonamiento del sistema.
No obstante, el nuevo algoritmo abierto no revela los pesos exactos para cada comportamiento, aunque la versión de 2023 sí lo hacía.
Referencia de la versión anterior: un reporte = 738 me gusta
Veamos los datos de 2023. Aunque están desactualizados, ilustran cómo el algoritmo valora las acciones.
El 5 de abril de 2023, X publicó en GitHub un conjunto de datos de pesos.
Estos son los números:
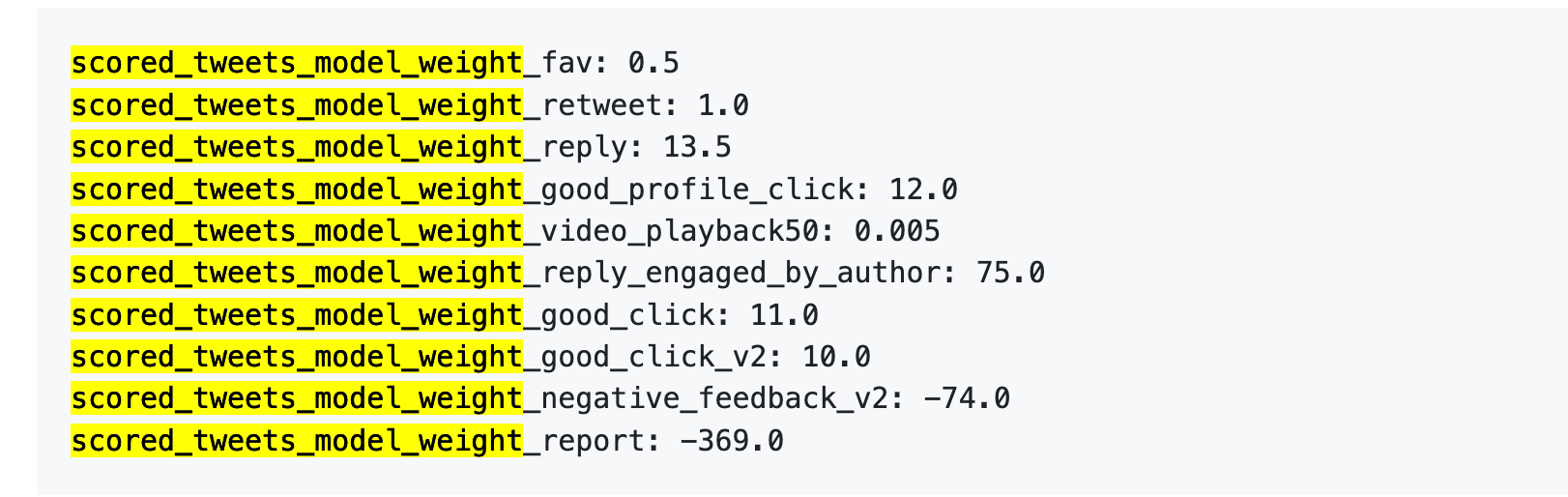
En resumen:
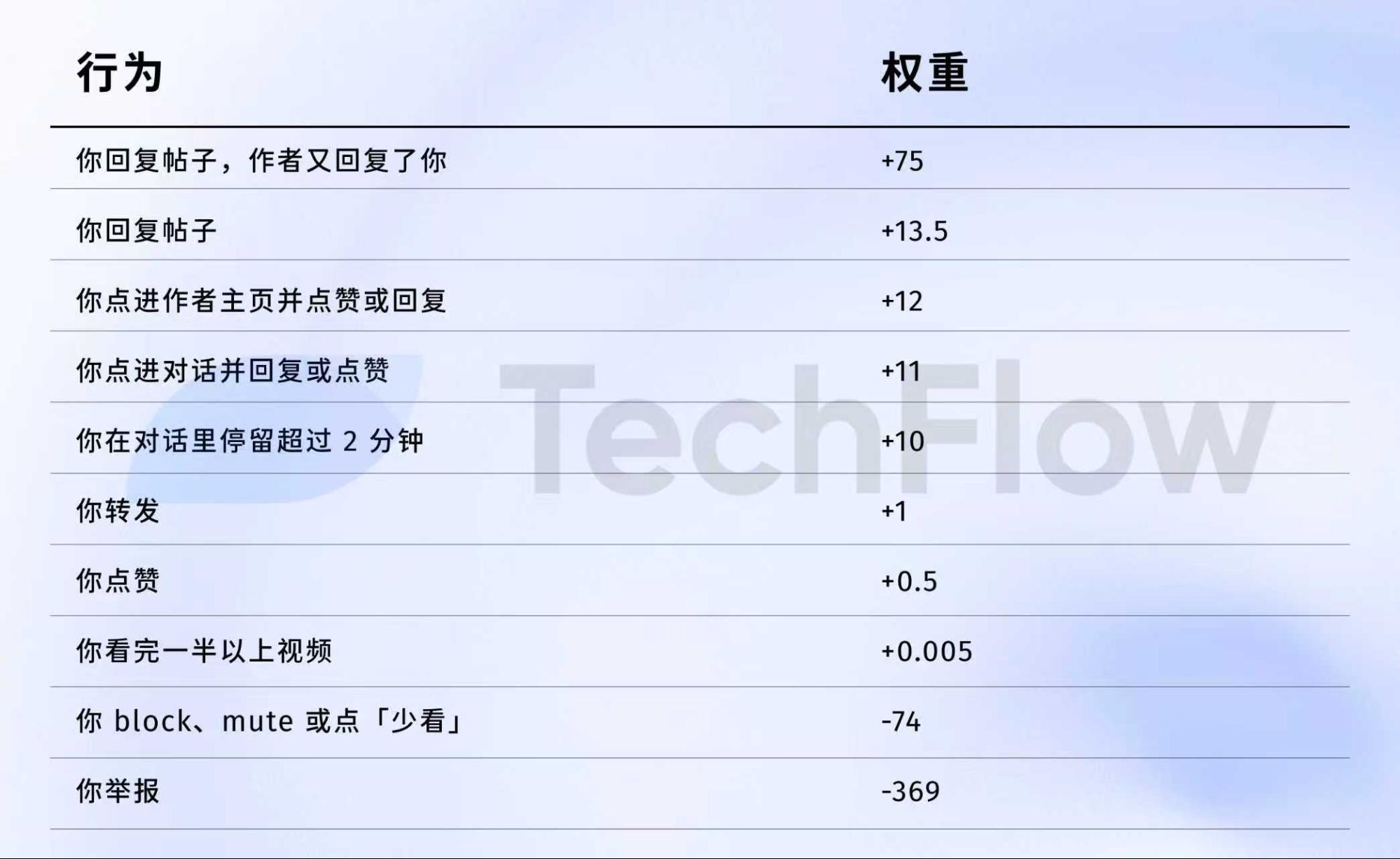
Fuente: versión anterior repositorio GitHub twitter/the-algorithm-ml. Haz clic para ver el algoritmo original.
Hay varios datos clave:
Primero, los me gusta apenas cuentan. El peso es solo 0,5, el más bajo entre las acciones positivas. El algoritmo los considera casi irrelevantes.
Segundo, lo que importa es la conversación. “Tú respondes y el autor responde” tiene un peso de 75, es decir, 150 veces más que un me gusta. El algoritmo valora mucho más la conversación bidireccional que los simples me gusta.
Tercero, la retroalimentación negativa penaliza mucho. Un bloqueo o silencio (-74) requiere 148 me gusta para compensarse. Un reporte (-369) necesita 738 me gusta. Estas penalizaciones se acumulan en la reputación de tu cuenta y afectan la distribución futura de tus publicaciones.
Cuarto, la tasa de finalización de vídeo apenas importa: solo 0,005, casi insignificante. Contrasta con plataformas como TikTok, donde la tasa de finalización es central.
El documento oficial añade: “Los pesos exactos pueden ajustarse en cualquier momento… Desde entonces, se han modificado periódicamente para optimizar los indicadores de la plataforma”.
Los pesos pueden cambiar en cualquier momento, y así ha sido.
La nueva versión no revela valores, pero la lógica del README es la misma: acciones positivas suman, negativas restan, y la puntuación final es una suma ponderada.
Los números pueden variar, pero el orden relativo se mantiene: responder a un comentario ajeno vale más que recibir 100 me gusta. Ser bloqueado es peor que no tener interacción.
¿Qué deben hacer los creadores con esta información?
Tras analizar el código de los algoritmos antiguo y nuevo de Twitter, estas son las recomendaciones prácticas:
1. Responde a tus comentaristas. “El autor responde al comentarista” es la acción con mayor puntuación (+75), 150 veces más valiosa que un me gusta. No hace falta pedir comentarios, pero responde siempre que alguien comente, aunque solo sea “gracias”: el algoritmo lo cuenta.
2. Evita que los usuarios te bloqueen. Un bloqueo necesita 148 me gusta para compensarse. El contenido polémico puede generar interacción, pero si esa interacción es “esta persona me molesta, bloqueo”, tu reputación sufrirá y afectará la distribución de tus publicaciones futuras. La controversia es un arma de doble filo: piénsalo antes de provocar.
3. Pon los enlaces externos en los comentarios. El algoritmo no quiere que los usuarios salgan de la plataforma. Incluir enlaces en el texto principal penaliza—Musk lo ha confirmado públicamente. Si quieres dirigir tráfico, pon tu contenido principal en la publicación y el enlace en el primer comentario.
4. No hagas spam. El nuevo código incluye un Author Diversity Scorer, que penaliza publicaciones consecutivas del mismo autor. El objetivo es diversificar los feeds, así que es mejor publicar una pieza de calidad que diez seguidas.
6. Ya no hay “mejor horario de publicación”. El algoritmo antiguo utilizaba el “horario de publicación” como característica manual, pero Phoenix lo ha eliminado. Phoenix solo observa el comportamiento del usuario, no el momento. Así que esas estrategias de “martes a las 15:00” ya no son relevantes.
Esto es lo que puede deducirse del código.
Existen también reglas de bonificación y penalización en la documentación pública de X que no figuran en este código abierto: la verificación con check azul aumenta el alcance, los mensajes en mayúsculas se penalizan y el contenido sensible reduce el alcance en un 80 %. Estas reglas no son públicas, por lo que no se incluyen aquí.
En conjunto, esta publicación de código abierto es relevante.
Incluye la arquitectura del sistema, lógica de recuperación de contenido candidato, proceso de puntuación y ranking, y varios filtros. El código está en Rust y Python, con estructura clara y un README más detallado que muchos proyectos comerciales.
Sin embargo, faltan elementos clave.
1. Los parámetros de peso no son públicos. El código solo explica que “las acciones positivas suman, las negativas restan”, pero no especifica cuánto vale un me gusta o un bloqueo. La versión de 2023 al menos mostraba los números; ahora solo la estructura de la fórmula.
2. Los pesos del modelo no son públicos. Phoenix usa el transformador Grok, pero los parámetros del modelo no se incluyen. Se ve cómo se llama al modelo, pero no cómo funciona por dentro.
3. Los datos de entrenamiento no son públicos. No se sabe qué datos se usaron, cómo se muestreó el comportamiento, ni cómo se construyeron las muestras positivas y negativas.
En definitiva, esta publicación de código abierto explica que “usamos sumas ponderadas para calcular puntuaciones”, pero no los pesos reales; y que “usamos transformadores para predecir probabilidades de comportamiento”, pero no cómo es el transformador internamente.
En comparación, TikTok e Instagram no han publicado ni esto. La publicación de X es más completa que la de otras grandes plataformas, aunque no es totalmente transparente.
Aun así, el código abierto aporta valor. Para creadores e investigadores, poder revisar el código es mejor que no tener acceso.
Declaración:
- Este artículo es una reproducción de [TechFlow], con derechos de autor del autor original [David]. Si tienes alguna duda sobre esta reproducción, contacta al equipo de Gate Learn, que lo gestionará según los procedimientos pertinentes.
- Aviso legal: Las opiniones expresadas en este artículo pertenecen exclusivamente al autor y no constituyen asesoramiento de inversión.
- Las versiones en otros idiomas de este artículo han sido traducidas por el equipo de Gate Learn. Sin mención explícita de Gate, no copies, distribuyas ni plagies el artículo traducido.
Compartir


Artículos relacionados

Cómo encontrar nuevas memecoins antes de que se vuelvan virales

Todos los ETF de cripto de EE. UU. que necesitas conocer en 2025

El Subir y Perspectivas de las Criptomonedas de IA de Próxima Generación

XRP Surge, A Review of 9 Projects with Related Ecosystems

Juegos narrativos: ¿cuál es el próximo intercambio?
