Xのオープンソース推薦アルゴリズムの仕組み:実際に注目を集めるコンテンツとは
1月20日午後、Xは最新のレコメンデーションアルゴリズムをオープンソース化しました。
マスク氏は「このアルゴリズムはまだ未熟で大幅な改善が必要だと認識していますが、少なくとも私たちがリアルタイムで改善に取り組んでいる様子を公開しています。他のソーシャルプラットフォームは決してこれをしないでしょう」とコメントしています。
この発言には2つのポイントがあります。まず、アルゴリズムの課題を認めていること。次に、透明性を大きな強みとしていることです。
今回の公開はXとして2回目のアルゴリズムオープンソース化です。2023年版は3年間更新がなく、本番環境からも切り離されていました。今回はコードベースを全面的に刷新し、コアモデルを従来の機械学習からGrokトランスフォーマーへと移行しました。公式説明では「手動による特徴量エンジニアリングは完全に排除されています」とされています。
簡単に言えば、従来のアルゴリズムはエンジニアが手動でパラメータを調整していましたが、現在はAIがあなたのインタラクション履歴を直接解析し、コンテンツをプロモートするかどうかを判断します。
クリエイターにとって、「最適な投稿時間」や「フォロワーが増えるタグ」といった戦略は、もはや効果的でない可能性があります。
また、オープンソース化されたGitHubリポジトリを確認し、AIのサポートでコード内にハードコーディングされたロジックをいくつか発見しました。
アルゴリズムロジックの変化:手動ルールからAI主導の判断へ
議論の混乱を避けるため、まず旧バージョンと新バージョンの違いを明確にします。
2023年、TwitterのオープンソースアルゴリズムはHeavy Rankerと呼ばれていました。これは伝統的な機械学習で、エンジニアが「投稿に画像が含まれているか」「著者のフォロワー数」「投稿からの経過時間」「リンクの有無」など数百の特徴量を手動で定義していました。
各特徴には重みが割り当てられ、最も効果的な組み合わせを見つけるために継続的に調整されていました。
新しいオープンソース版はPhoenixと呼ばれます。アーキテクチャは全く異なり、大規模AIモデルに大きく依存するアルゴリズムです。コアにはGrokトランスフォーマーが使われており、これはChatGPTやClaudeと同種の技術です。
公式READMEには「すべての手動で設計された特徴量を排除しました」と明記されています。
手動で抽出したコンテンツ特徴量に依存する旧来のルールベースシステムは完全に廃止されました。
では、アルゴリズムはどのようにしてコンテンツの良し悪しを判断しているのでしょうか?
答えは「あなたの行動履歴」です。どの投稿に「いいね」したか、誰に返信したか、2分以上閲覧した投稿、ブロックしたアカウントの種類など、Phoenixはこれらの行動をトランスフォーマーに入力し、モデルがパターンを学習・要約します。
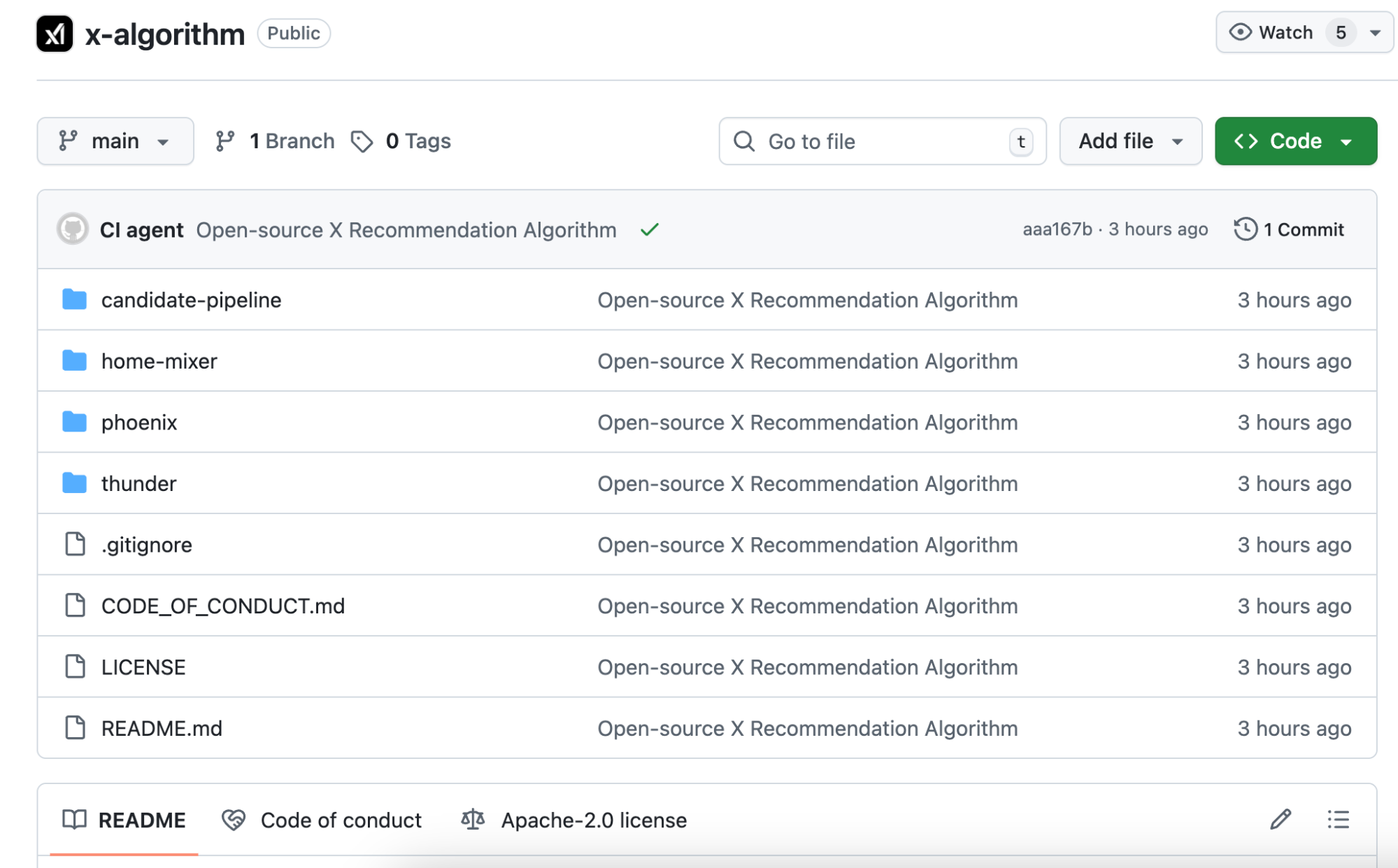
旧アルゴリズムは手作業で作られたスコアカードのように、各条件にポイントを付与していました。
新しいアルゴリズムは、あなたの全ブラウジング履歴にアクセスできるAIが、次に何を見たいかを予測するようなものです。
クリエイターにとっては、以下の2点が重要になります。
第一に、「ベストな投稿時間」や「ゴールデンタグ」といった戦術の価値が大きく低下します。モデルはもはや固定された特徴ではなく、各ユーザーの個別の好みを参照するからです。
第二に、あなたのコンテンツがプロモートされるかどうかは「ユーザーがどのように反応するか」に大きく依存します。これらの反応は15種類の行動予測として数値化されており、次で詳しく説明します。
アルゴリズムが予測する15種類のユーザー反応
Phoenixが投稿をレコメンドする際、15種類のユーザー行動を予測します:
- ポジティブな行動:いいね、返信、リポスト、引用リポスト、投稿クリック、著者プロフィールクリック、動画の半分以上視聴、画像展開、シェア、一定時間の滞在、著者のフォロー
- ネガティブな行動:「興味なし」を選択、著者をブロック、著者をミュート、報告
各行動には予測確率が割り当てられます。たとえば、ある投稿を「いいね」する確率が60%、著者をブロックする確率が5%とモデルが推定する場合があります。
アルゴリズムは各確率に対応する重みを掛け、その合計を最終スコアとします。
数式は以下の通りです:
最終スコア = Σ(重み × P(行動))
ポジティブな行動には正の重み、ネガティブな行動には負の重みが設定されています。
合計スコアが高い投稿ほど上位に表示され、低いものは下位に押し下げられます。
実際には、コンテンツの「良し悪し」はもはや内容そのものだけで決まるわけではありません(シェアされるためには可読性や価値が前提条件ですが)。むしろ「あなたのコンテンツがどんな反応を引き起こすか」で決まります。アルゴリズムはコンテンツ自体ではなく、ユーザーの行動に注目しています。
このロジックを極端に捉えると、低品質でも多くの返信を生み出す投稿は、反応のない高品質投稿よりも高いスコアになる場合があります。これがシステムの根本的なロジックかもしれません。
ただし、新しいオープンソースアルゴリズムでは各行動の正確な重みは開示されていませんが、2023年版では公開されていました。
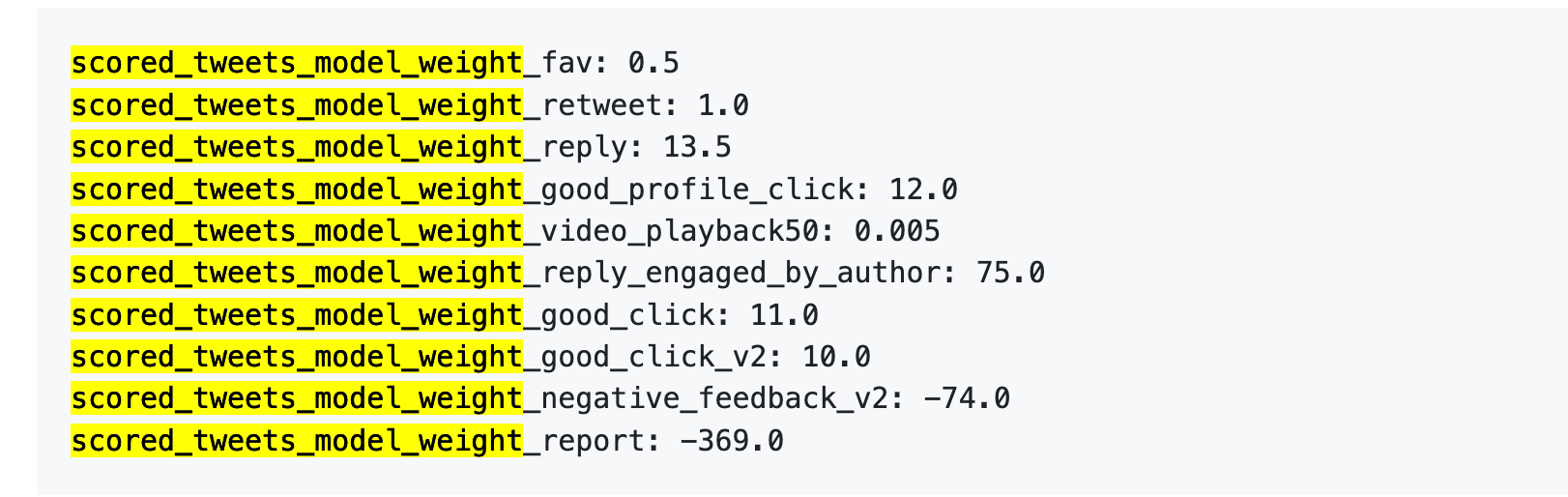
旧バージョン参照:1件の報告 = 738件のいいね
2023年のデータセットを見てみましょう。情報は古いですが、アルゴリズムが各行動をどのように評価しているかが分かります。
2023年4月5日、Xは重みデータをGitHubで公開しました。
主な数値は以下の通りです:
要約すると:
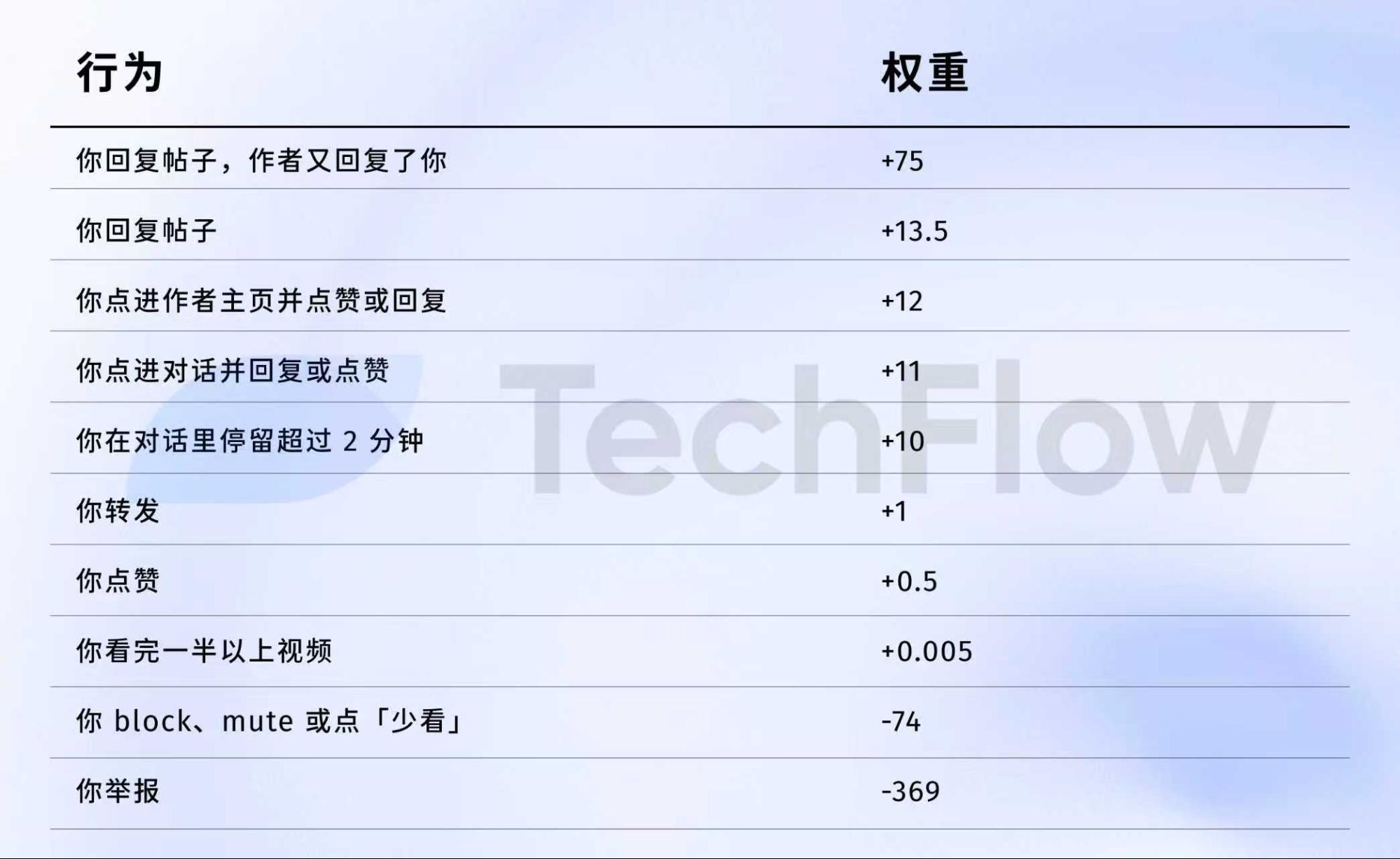
データ出典:旧バージョン GitHub twitter/the-algorithm-ml repository。元のアルゴリズムはこちら。
注目すべき数値は次の通りです:
第一に、「いいね」はほとんど価値がありません。重みは0.5で、ポジティブ行動の中で最も低いです。アルゴリズムは「いいね」をほぼ無価値と見なしています。
第二に、会話が重要視されています。「あなたが返信し、著者がさらに返信する」行動の重みは75で、「いいね」の75~150倍です。アルゴリズムは双方向の会話を「いいね」よりはるかに重視しています。
第三に、ネガティブフィードバックのペナルティは非常に大きいです。1件のブロックまたはミュート(-74)は、148件の「いいね」でようやく相殺されます。1件の報告(-369)は、738件の「いいね」が必要です。これらのネガティブスコアはアカウントの評価に蓄積され、今後の投稿配信にも影響します。
第四に、動画完了率の重みは極めて低く、わずか0.005です。ほぼ無視できるレベルで、TikTokのような完了率を重視するプラットフォームとは対照的です。
公式ドキュメントにも「ファイル内の正確な重みはいつでも調整可能…以降、プラットフォーム指標の最適化のため定期的に重みを調整している」と記載されています。
重みは随時変更可能で、実際に変更されています。
新バージョンでは具体的な数値は非公開ですが、READMEのロジックフレームワークは同じです。ポジティブ行動は加点、ネガティブ行動は減点、最終スコアは重み付き合計です。
具体的な数値は変わっても、相対的な順位は変わらない可能性が高いです。他人のコメントに返信する方が、100件の「いいね」より価値があります。ブロックされることは、何の反応もないよりも悪影響です。
クリエイターはこの情報をどう活用すべきか?
新旧Twitterアルゴリズムのコードを確認したうえで、実践的なポイントをまとめます:
1. コメントには必ず返信しましょう。重みテーブルでは「著者がコメント者に返信」は最高得点(+75)で、「いいね」の150倍の価値があります。コメントを促す必要はありませんが、誰かがコメントしたら必ず返信しましょう。簡単な「ありがとう」でもアルゴリズムはカウントします。
2. ユーザーにブロックされるような投稿は避けましょう。1件のブロックは148件の「いいね」でようやく相殺されます。議論を呼ぶ投稿はエンゲージメントを生みますが、「この人は不快だからブロック」となれば、アカウント評価に長期的なダメージとなり、今後の配信にも影響します。炎上は諸刃の剣なので、慎重に判断しましょう。
3. 外部リンクはコメント欄に入れましょう。アルゴリズムはユーザーがプラットフォーム外に離脱することを嫌います。本文にリンクを入れるとペナルティを受けます(マスク氏も公言済み)。トラフィックを流したい場合は、投稿本文に主な内容を書き、リンクは最初のコメントに載せましょう。
4. スパム投稿は避けましょう。新コードにはAuthor Diversity Scorerが実装されており、同一著者による連続投稿はペナルティとなります。ユーザーのフィード多様化が目的なので、質の高い投稿を1つ出す方が連投10件より有利です。
6. もはや「ベストな投稿時間」は存在しません。旧アルゴリズムでは「投稿時間」が手動特徴量でしたが、Phoenixでは完全に廃止されています。Phoenixは投稿タイミングではなくユーザー行動だけを見るため、「火曜15時」戦略の有効性は大きく低下しています。
以上がコードから読み取れる内容です。
また、Xの公開ドキュメントには今回のオープンソースには含まれないボーナス・ペナルティルールもあります。ブルーチェック認証はリーチを増やし、全大文字投稿はペナルティ、センシティブな内容はリーチが80%減少します。これらのルールはオープンソース対象外のため、ここでは扱いません。
全体として、今回のオープンソース公開は非常に充実しています。
システム全体のアーキテクチャ、候補コンテンツのリコールロジック、スコアリングとランキングのプロセス、各種フィルターまで含まれています。コードは主にRustとPythonで記述されており、構造も明確でREADMEは多くの商用プロジェクトより詳細です。
ただし、いくつか重要な要素が欠けています。
1. 重みパラメータが非公開です。コードでは「ポジティブ行動は加点、ネガティブ行動は減点」とだけ説明されており、「いいね」や「ブロック」がどれだけの価値かは不明です。2023年版では数値が開示されていましたが、今回は数式フレームワークのみです。
2. モデル重みも非公開です。PhoenixはGrokトランスフォーマーを使用していますが、モデルパラメータは含まれていません。モデルの呼び出し方法は見られますが、内部構造は不明です。
3. 学習データも非公開です。どのデータで学習されたのか、ユーザー行動のサンプリング方法や正例・負例の構築方法も不明です。
つまり、今回のオープンソース公開は「重み付き合計でスコアを算出する」ことは示していますが、実際の重みは非公開。「トランスフォーマーで行動確率を予測する」ことは示していますが、トランスフォーマーの中身は分かりません。
比較すると、TikTokやInstagramはここまでの情報すら公開していません。Xのオープンソース公開は他の主要プラットフォームよりも確かに包括的ですが、完全な透明性とは言えません。
とはいえ、オープンソース化は依然として価値があります。クリエイターや研究者にとって、コードを確認できるだけでも、情報非公開よりはるかに有意義です。
ステートメント:
- 本記事は[TechFlow]より転載しており、著作権は原著者[David]に帰属します。転載に関するご意見がある場合は、Gate Learnチームまでご連絡ください。関連手続きに従い速やかに対応いたします。
- 免責事項:本記事に記載された見解および意見は著者個人のものであり、投資助言を構成するものではありません。
- 本記事の他言語版はGate Learnチームによる翻訳です。Gateの明記がない限り、翻訳記事の無断転載・配布・盗用を禁止します。
共有


関連記事

XRPサージ、関連エコシステムを持つ9つのプロジェクトのレビュー

次世代AI暗号通貨の成長と展望

ヴァイラルになる前に新しいメメコインを見つける方法

Gate Research: 週間ホットトピック(2025年2月24日-28日)

ナラティブゲーム:次の取引は何ですか?
