No interior do algoritmo de recomendações open-source da X: que conteúdos conseguem, de facto, captar a atenção?
Na tarde de 20 de janeiro, a X disponibilizou em open source o seu mais recente algoritmo de recomendação.
Musk comentou: “Sabemos que este algoritmo é limitado e ainda requer grandes melhorias, mas pelo menos pode ver-nos a trabalhar para o aperfeiçoar em tempo real. Outras plataformas sociais não teriam coragem para isto.”
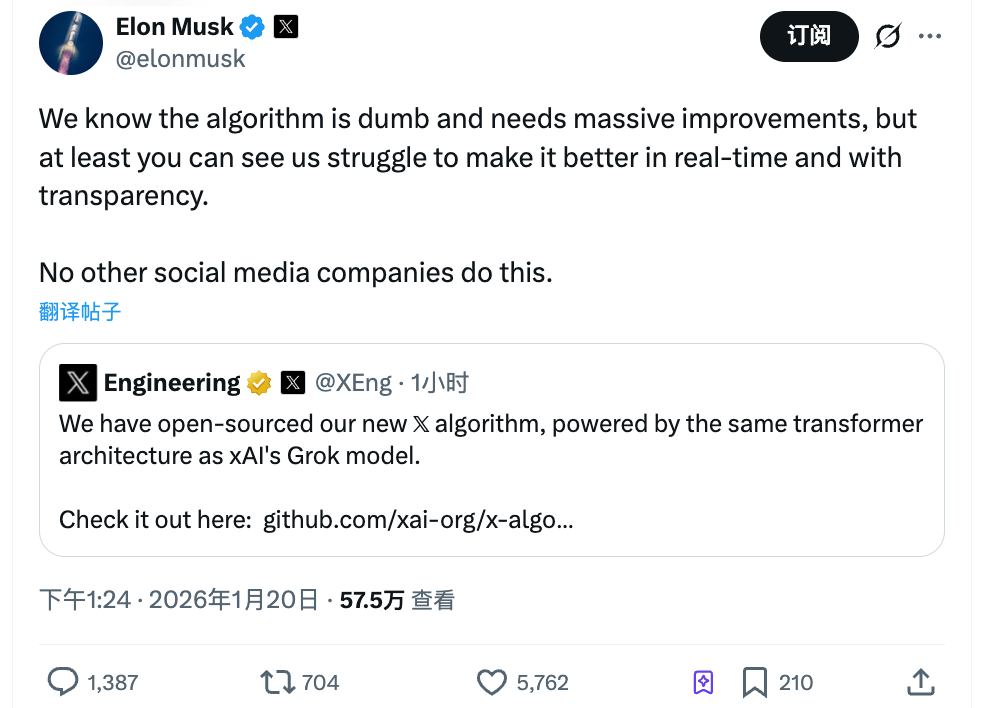
A afirmação de Musk tem dois pontos essenciais. Primeiro, reconhece as limitações do algoritmo. Segundo, apresenta a transparência como fator diferenciador.
Esta é a segunda vez que a X disponibiliza o seu algoritmo em open source. A versão de 2023 esteve três anos sem atualizações e já não estava integrada no sistema de produção. Desta vez, todo o código foi reescrito. O modelo central passou do machine learning tradicional para o transformador Grok. Segundo a descrição oficial, “a engenharia manual de funcionalidades foi completamente eliminada.”
De forma simples: o algoritmo anterior dependia de ajustes manuais feitos por engenheiros. Agora, a IA analisa diretamente o histórico de interações do utilizador para decidir se promove ou não o conteúdo.
Para criadores de conteúdo, isto significa que estratégias como “melhores horários para publicar” ou “que tags aumentam seguidores” podem já não ser eficazes.
Analisámos também o repositório open source no GitHub e, com recurso à IA, identificámos alguma lógica hard-coded no código que merece ser analisada.
Mudança de Lógica Algorítmica: Das Regras Manuais ao Julgamento por IA
Antes de mais, importa clarificar as diferenças entre a versão anterior e a nova, para evitar confusões na análise seguinte.
Em 2023, o algoritmo open source do Twitter chamava-se Heavy Ranker. Era, fundamentalmente, machine learning tradicional. Os engenheiros definiam manualmente centenas de funcionalidades: se a publicação tinha imagens, o número de seguidores do autor, a antiguidade da publicação, se continha links, entre outros.
Cada funcionalidade recebia um peso, que era ajustado continuamente até encontrar a combinação mais eficaz.
Esta nova versão open source chama-se Phoenix. A arquitetura é totalmente diferente—pode encará-la como um algoritmo muito mais dependente de grandes modelos de IA. O núcleo utiliza o transformador Grok, o mesmo tipo de tecnologia por trás do ChatGPT e do Claude.
O README oficial é claro: “Eliminámos todas as funcionalidades desenhadas manualmente.”
O sistema anterior, baseado em regras e extração manual de funcionalidades do conteúdo, foi eliminado por completo.
Então, como é que o algoritmo avalia se o conteúdo é relevante?
A resposta: a sequência de comportamentos do utilizador. O que gostou, a quem respondeu, em que publicações permaneceu mais de dois minutos, que perfis bloqueou. O Phoenix utiliza estes comportamentos para alimentar o transformador, permitindo ao modelo aprender e sintetizar padrões.
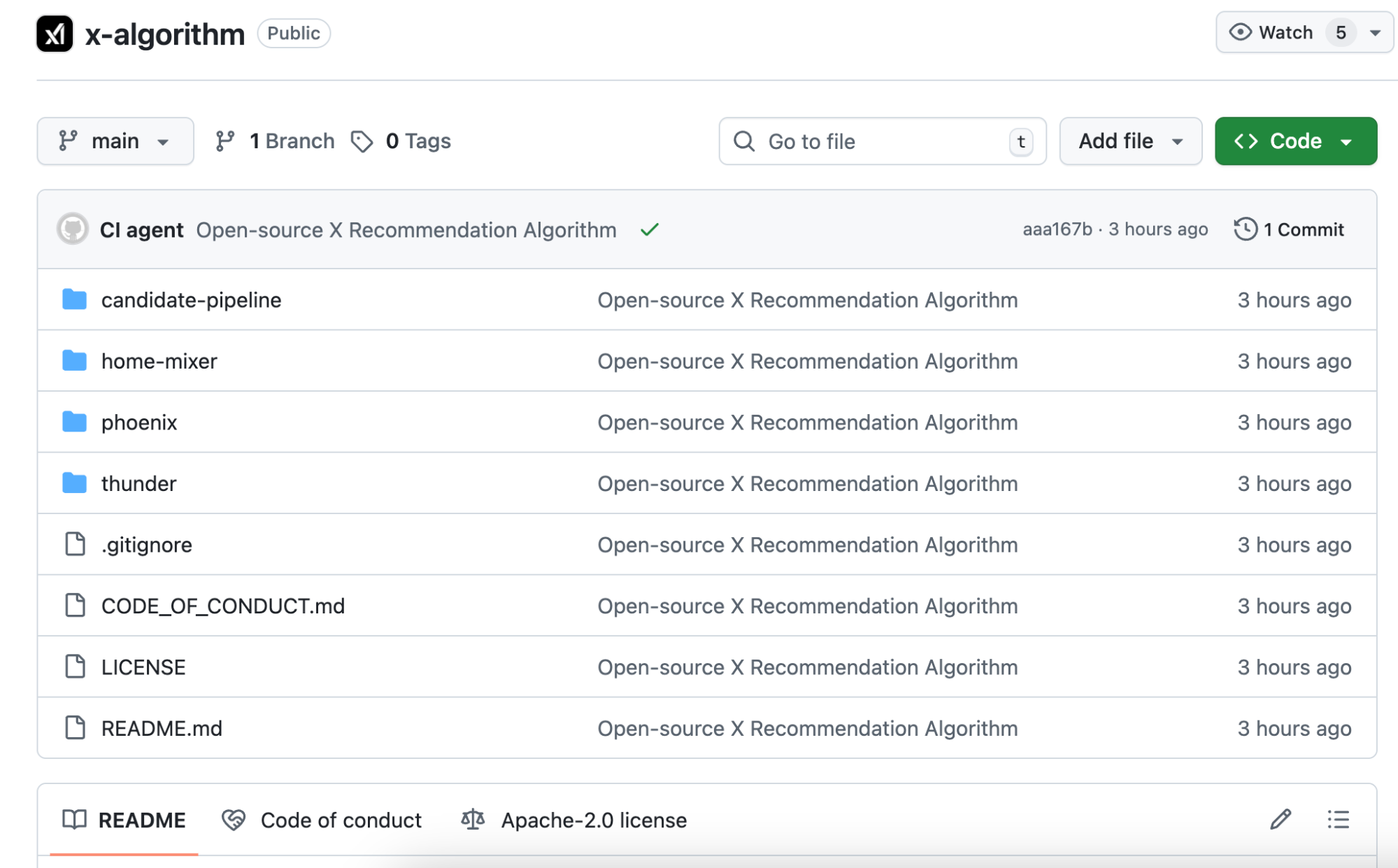
Para ilustrar: o algoritmo antigo funcionava como uma folha de pontuação manual, atribuindo pontos por cada critério cumprido.
O novo algoritmo funciona como uma IA com acesso ao seu histórico de navegação, prevendo o que vai querer ver a seguir.
Para criadores, isto traduz-se em dois aspetos:
Primeiro, táticas como “melhor hora para publicar” ou “tags de ouro” têm agora muito menos impacto. O modelo já não avalia funcionalidades fixas, mas sim as preferências individuais de cada utilizador.
Segundo, a promoção do conteúdo depende sobretudo de “como os utilizadores reagem ao seu conteúdo”. Estas reações são quantificadas em 15 tipos de previsões comportamentais, que detalhamos de seguida.
O Algoritmo Prevê 15 Tipos de Reação do Utilizador
Quando o Phoenix avalia uma publicação para recomendação, estima 15 possíveis ações do utilizador:
- Ações positivas: gostar, responder, republicar, citar republicação, clicar na publicação, clicar no perfil do autor, ver mais de metade de um vídeo, expandir imagem, partilhar, permanecer durante um determinado tempo, seguir o autor
- Ações negativas: selecionar “não interessado”, bloquear o autor, silenciar o autor, denunciar
Cada ação tem uma probabilidade prevista. Por exemplo, o modelo pode estimar uma probabilidade de 60% de gostar de uma publicação e de 5% de bloquear o autor.
O algoritmo multiplica cada probabilidade pelo respetivo peso e soma o resultado para obter a pontuação final.
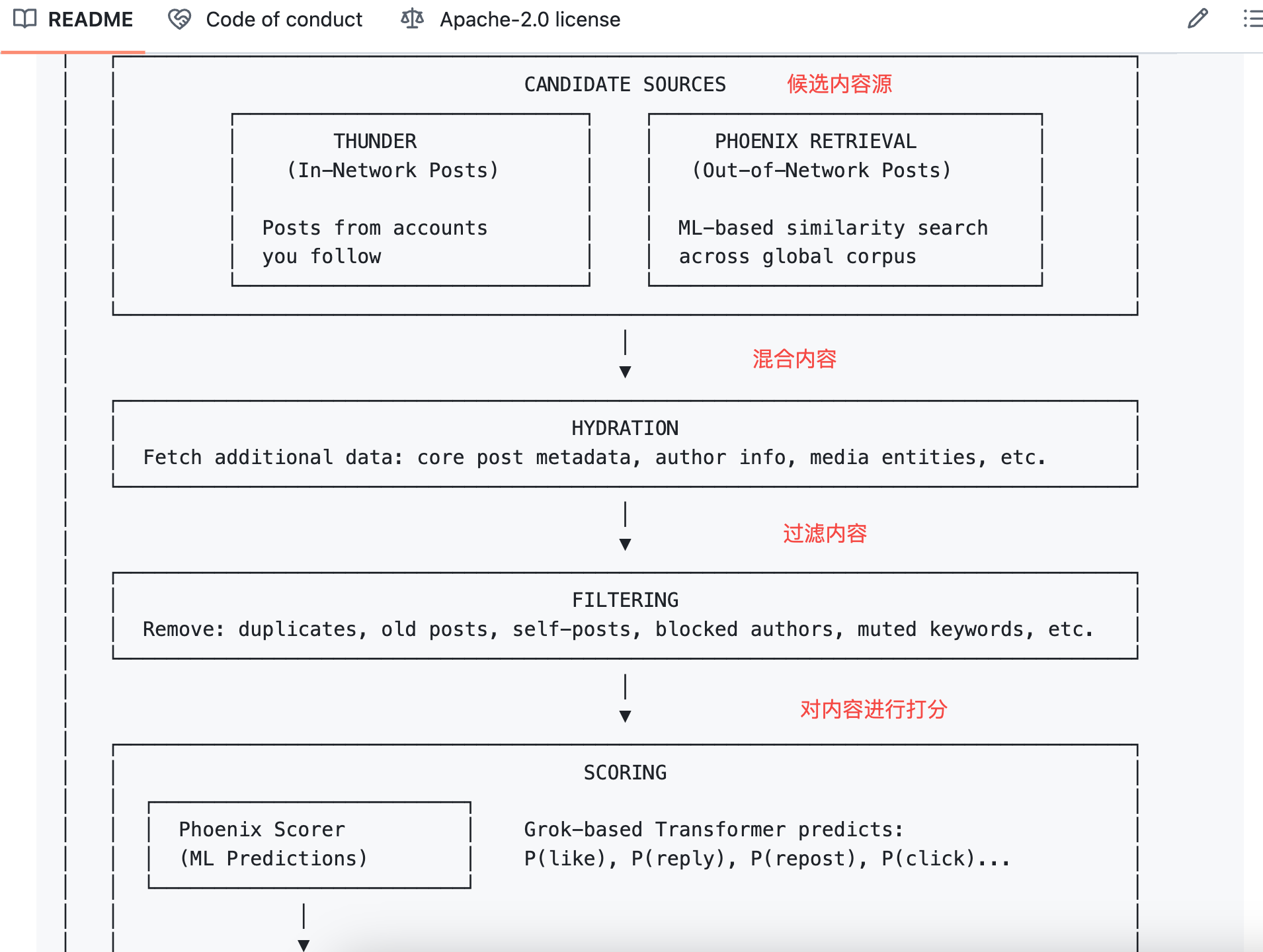
A fórmula é:
Pontuação Final = Σ ( peso × P(açao) )
Ações positivas têm pesos positivos; ações negativas têm pesos negativos.
As publicações com pontuação total mais alta são promovidas; as com pontuação mais baixa são relegadas.
Na prática, a “qualidade” do conteúdo já não depende apenas do seu valor intrínseco (embora legibilidade e relevância continuem a ser pré-requisitos para partilha). Agora, depende das “reações que o seu conteúdo provoca”. O algoritmo foca-se no comportamento do utilizador, não no conteúdo em si.
Com esta lógica, em casos extremos, uma publicação de baixa qualidade que gera muitas respostas pode obter uma pontuação superior a uma publicação de alta qualidade sem qualquer interação. Esta pode ser a lógica subjacente do sistema.
No entanto, o novo algoritmo open source não divulga os pesos exatos de cada comportamento, ao contrário da versão de 2023.
Referência da Versão Anterior: Uma Denúncia = 738 Gostos
Analisemos o conjunto de dados de 2023. Embora já desatualizado, ilustra como o algoritmo valorizava diferentes ações.
A 5 de abril de 2023, a X divulgou publicamente um conjunto de pesos no GitHub.
Eis os números:
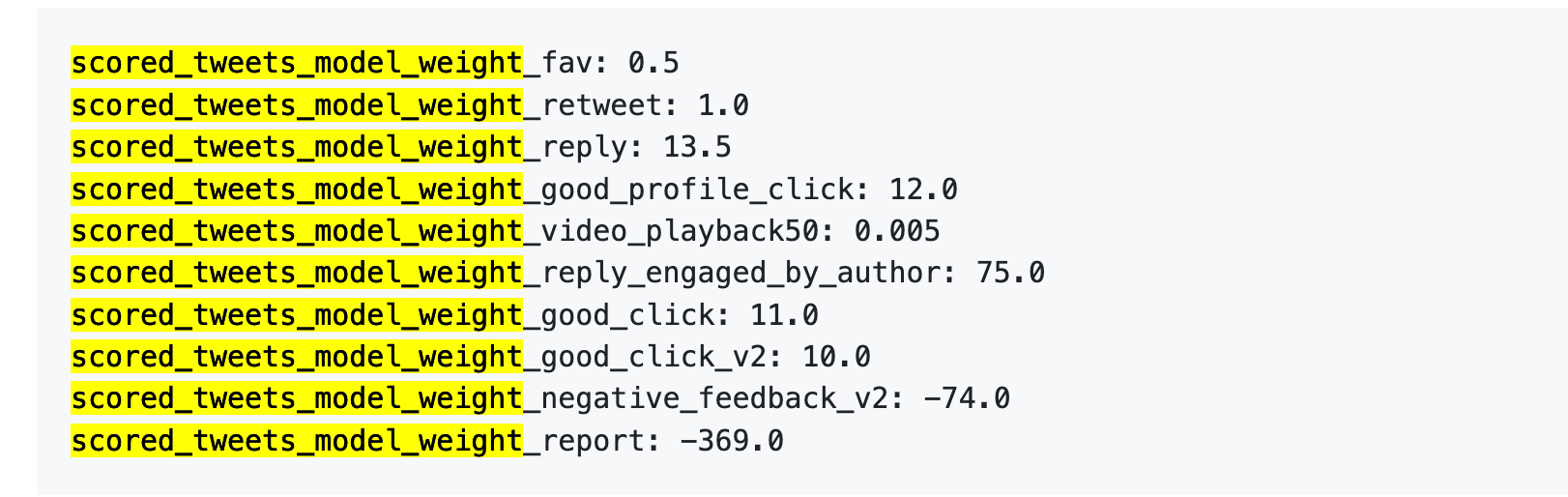
Em resumo:
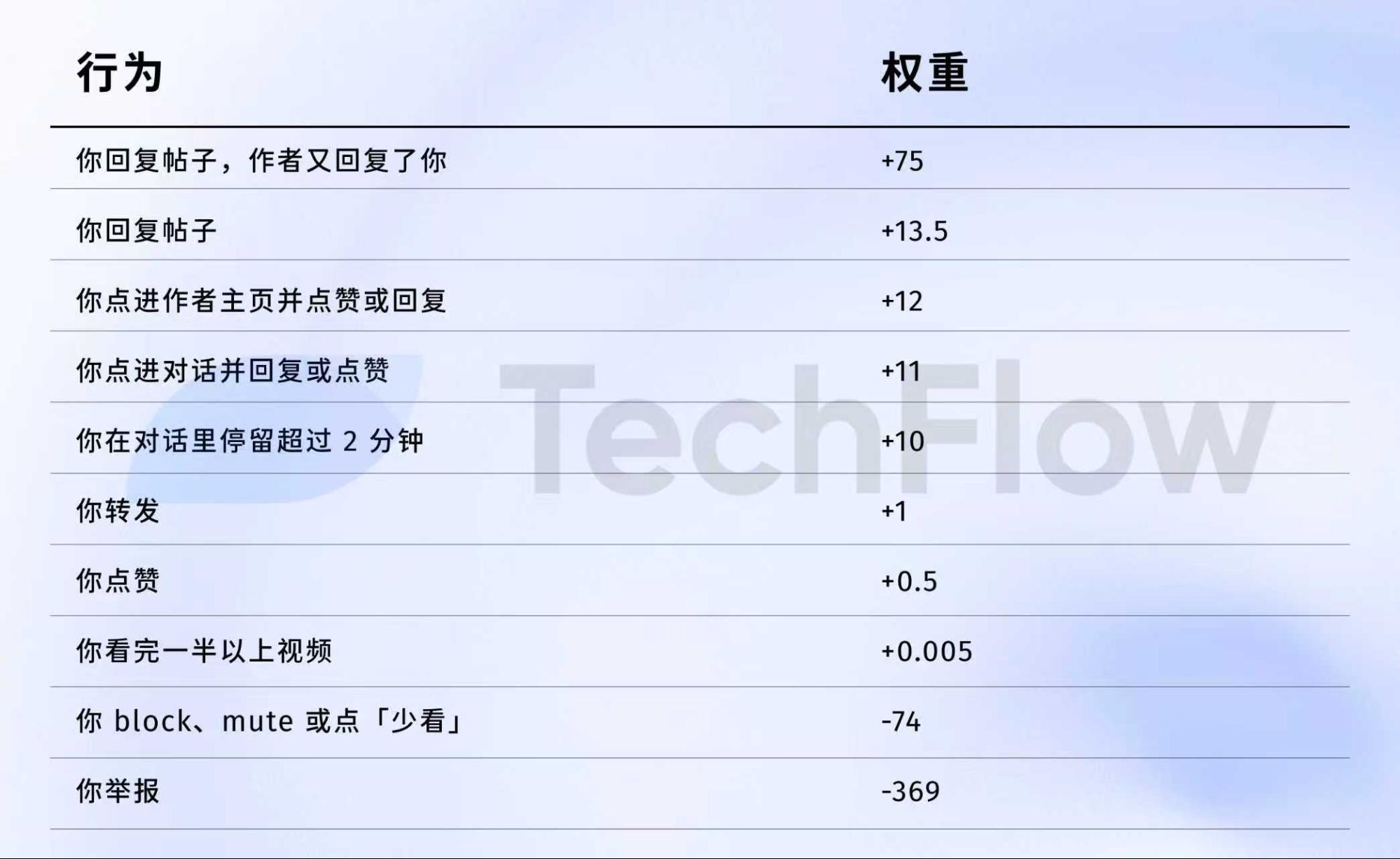
Fonte dos dados: Versão anterior repositório GitHub twitter/the-algorithm-ml. Clique para consultar o algoritmo original.
Alguns números merecem destaque:
Primeiro, os gostos têm valor quase nulo. O peso é apenas 0,5, o mais baixo entre as ações positivas. O algoritmo considera um gosto praticamente irrelevante.
Segundo, a conversação é o que mais conta. “Responder e o autor responder de volta” tem um peso de 75—150 vezes mais do que um gosto. O algoritmo valoriza muito mais as conversas bidirecionais do que simples gostos.
Terceiro, o feedback negativo implica uma penalização severa. Um bloqueio ou silenciamento (-74) requer 148 gostos para compensar. Uma denúncia (-369) exige 738 gostos. Estas pontuações negativas acumulam-se na reputação da conta, afetando a distribuição futura das publicações.
Quarto, a taxa de conclusão de vídeo tem um peso extremamente baixo—apenas 0,005, praticamente irrelevante. Isto contrasta fortemente com plataformas como o TikTok, que valorizam a taxa de conclusão como métrica central.
O documento oficial refere ainda: “Os pesos exatos podem ser ajustados a qualquer momento… Desde então, temos ajustado periodicamente os pesos para otimizar os indicadores da plataforma.”
Os pesos podem ser alterados em qualquer altura—e têm sido.
A nova versão não divulga valores específicos, mas a lógica no README mantém-se: ações positivas somam pontos, negativas subtraem, e a pontuação final resulta de uma soma ponderada.
Os valores exatos podem variar, mas a ordem relativa mantém-se. Responder a comentários é mais valioso do que obter 100 gostos. Ser bloqueado é pior do que não ter qualquer interação.
O Que Devem Fazer os Criadores com Esta Informação?
Após analisar o código do algoritmo antigo e novo do Twitter, eis alguns pontos práticos a reter:
1. Responda aos seus comentadores. Na tabela de pesos, “autor responde ao comentador” é a ação de maior valor (+75), 150 vezes mais relevante do que um gosto. Não precisa de pedir comentários, mas deve sempre responder se alguém comentar—até um simples “obrigado” conta para o algoritmo.
2. Evite ser bloqueado pelos utilizadores. Um bloqueio exige 148 gostos para ser compensado. Conteúdo controverso pode gerar interação, mas se essa interação for “esta pessoa incomoda, bloquear”, a reputação da conta sofre a longo prazo, afetando toda a distribuição futura das publicações. A controvérsia é uma faca de dois gumes—pese bem antes de provocar.
3. Coloque links externos nos comentários. O algoritmo penaliza publicações com links no texto principal—Musk confirmou-o publicamente. Se pretende gerar tráfego, coloque o conteúdo principal na publicação e o link no primeiro comentário.
4. Não faça spam. O novo código inclui um Author Diversity Scorer, que penaliza publicações consecutivas do mesmo autor. O objetivo é diversificar o feed dos utilizadores, pelo que é preferível publicar uma peça de qualidade do que várias seguidas.
6. Deixou de existir “melhor hora para publicar”. O algoritmo anterior considerava a “hora de publicação” como funcionalidade manual, mas o Phoenix eliminou esse fator. Agora, o Phoenix apenas avalia o comportamento do utilizador, não o momento da publicação. Estratégias como “terça-feira às 15h” são, por isso, cada vez menos relevantes.
É isto que se pode retirar do código.
Existem também regras de bónus e penalização na documentação pública da X que não constam nesta versão open source: a verificação blue check aumenta o alcance, publicações em maiúsculas são penalizadas e conteúdo sensível sofre uma redução de 80% no alcance. Estas regras não são open source, pelo que não são abordadas aqui.
No geral, esta versão open source é relevante.
Inclui toda a arquitetura do sistema, lógica de recall de conteúdo candidato, processo de pontuação e ordenação, e vários filtros. O código está principalmente em Rust e Python, com uma estrutura clara e um README mais detalhado do que muitos projetos comerciais.
No entanto, faltam elementos essenciais.
1. Os parâmetros de peso não são públicos. O código apenas explica que “ações positivas somam pontos, negativas subtraem”, mas não especifica o valor de um gosto ou de um bloqueio. A versão de 2023 divulgava os números; desta vez, só está disponível a estrutura da fórmula.
2. Os pesos do modelo não são públicos. O Phoenix utiliza o transformador Grok, mas os parâmetros do modelo não estão incluídos. Pode ver como o modelo é chamado, mas não o seu funcionamento interno.
3. Os dados de treino não são públicos. Não se sabe que dados foram usados para treinar o modelo, como foi feita a amostragem do comportamento dos utilizadores ou como foram construídas as amostras positivas e negativas.
Ou seja, esta versão open source informa que “usamos somas ponderadas para calcular pontuações”, mas não revela os pesos reais; informa que “usamos transformadores para prever probabilidades comportamentais”, mas não mostra o funcionamento interno do transformador.
Em comparação, TikTok e Instagram não divulgaram sequer esta informação. A versão open source da X é, de facto, mais abrangente do que as restantes grandes plataformas, mas ainda não é totalmente transparente.
Isso não significa que a abertura do código não tenha valor. Para criadores e investigadores, poder analisar o código é preferível a não ter qualquer acesso.
Declaração:
- Este artigo é republicado a partir de [TechFlow], sendo os direitos de autor do autor original [David]. Caso tenha alguma questão relativa a esta republicação, contacte a equipa Gate Learn, que dará seguimento atempadamente conforme os procedimentos em vigor.
- Declaração de exoneração de responsabilidade: As opiniões expressas neste artigo pertencem exclusivamente ao autor e não constituem aconselhamento de investimento.
- Outras versões linguísticas deste artigo são traduzidas pela equipa Gate Learn. Sem menção explícita de Gate, não copiar, distribuir ou plagiar o artigo traduzido.
Partilhar


Artigos relacionados

A Ascensão e Perspectivas de Criptomoedas de IA de Próxima Geração

Gate Research: Tópicos Quentes Semanais (24 a 28 de fevereiro de 2025)

XRP Surge, Uma Revisão de 9 Projetos com Ecossistemas Relacionados

Como encontrar novas memecoins antes de se tornarem virais

Tarifas de Trump explicadas: Como afetam o mercado de criptomoedas
